April 20, 2015
Docker – A Different Breed of Virtualization
From Wikipedia: Virtualization, in computing, refers to the act of creating a virtual (rather than actual) version of something, including but not limited to a virtual computer hardware platform, operating system (OS), storage device, or computer network resources.
Today we’re encountering virtualization in most of our computing environments. It provides valuable benefits for software development where one can isolate completely the runtime environment, thus keeping the host machine intact. In the web development world, virtualization is a “must-have” which enables companies to optimize server operation costs.
Unix (and *nix systems alike) does not strongly implement the principle of least privileged and the least common mechanism principle; most objects in Unix (including the processes) the file system, and the network stack are globally visible to all. This leads to a lack of configuration isolation: multiple applications can have conflicting requirements for system-wide configuration settings, or different versions of the same library (which is more problematic). Therefore a need to run these applications in separate environments arises.
In the current paper we would like to discuss about a different kind of virtualization: operating system level or container-based virtualization. In contrast with full hardware virtualization (like VMware ESXi, or QEMU), OS-level virtualization comes with lighter overhead compared with full hardware virtualization. Guests which are implemented as OS-level virtualized are also named containers – the community has taken this name and used it as container-based virtualization.
Here is a quick comparison of the two technologies (containers as OS-level virtualization and Virtual Machines – VMs as hardware virtualization) considering the pros and cons for each:
| Pros | Cons | |
| Containers |
|
|
| VMs |
|
|
There are several implementations available at the date of this paper for the container-base virtualization:
- LXC – Linux Containers
- OpenVZ
- Docker
Recently, Docker has come to our attention because of the way it augments this type of container based virtualization, introducing some useful novelty concepts like descriptive configuration files and the possibility to commit one’s updates on a container.Our main goal was to mimic as much as possible the “classical” setup of a web application deployment environment where we have separate server containers for the application server and the database server. Taking this concept one step further, we can integrate a load balancer and a second application server.
Linux containers – how they work?
Rather than running a full OS on a virtual hardware, container-based virtualization modifies an existing OS to provide extra isolation. This usually involves:
– adding a container ID to every process
– adding new access control checks to every syscall.
Thus Linux containers can be seen as another level of access control besides the users and groups-based access control. Linux container is a concept built on the kernel namespaces feature, which we try to describe below.
The best place to start is actually the description offered by Michael Kerrisk[1]. As said, the main isolation problem in traditional Unix-like systems is caused by using a single, global namespace for storing global system resources. Rather than having this, kernel developers started to wrap different types of system resources, so that the process within the namespace sees that resource as being global. In other words, a process which runs inside a certain namespace sees only the resources allocated to that namespace. This way isolation is achieved.The following types of namespaces are currently supported:
- Mount namespaces (for storage devices and drive mapping)
- UTS namespaces (for hostname and domain name)
- IPC namespaces (for inter-process communication)
- PID namespaces (for Process IDs)
- Network namespaces
- User namespaces
As we can see, the most important system resources are being wrapped so that a Linux container “thinks” it owns all the system resources.
[1] Author of “The Linux Programming Interface”, maintainer of the Linux man-pages project (https://en.wikipedia.org/wiki/Michael_Kerrisk)
Setup possibilities
The common setup implies a fully isolated container, which has no access to resources outside of the container. A process which runs inside the container will appear to run inside a normal Linux system, although the kernel is shared with processes located in different namespaces.
In contrast with a VM, a container can hold only one process. A container which has all the processes of a full system is called a system container, while a container with one application only is called an application container.
It is most convenient to share resources with the hosting system in case total isolation isn’t a requirement, for example bind mounts for shared storage; in case of a VM, the storage can be mounted only via NFS or SMB shares, adding an extra layer of indirection.
Security
Having namespaces for system resources make security simpler: a container cannot access what it cannot see. Additionally, the root user from within the container is considered different thant the root user of the host.
The main security bridge can come from system calls which aren’t namespace-aware. The system calls are still being audited for such cases.
These are the building-blocks for all Linux container-based virtualization providers; on top of this, container providers deploy high-level tools for managing containers and their images: creating, running, stopping, linking them, etc. Docker, OpenVZ, LSX – all of them are built on top of the kernel namespaces feature. Due to its feature set, Docker is probably the best management tool for containers.
Docker-izing applications and their environment
Our goal is to reproduce the environment in which a certain application runs: servers and their configuration, the links between them and a shared application configuration. In other words, from the application’s point of view the VE should look the same (in terms of configuration) as the real (let’s say production) environment.
Then, we want to be able to deploy and to access the application directly from the host machine. This makes it easier for:
– the developer to just start working on the application instead of polluting his host machine with all the needed configuration settings
– QA to simplify integration testing, especially for those cases where the application uses external services: they have their own version (which may not be yet in production), you want to test with real data, but not especially with the real environment, etc.
– devops to have a single setup which can be replicated on any host machine.
Our idea was to create a Docker setup which is:
– general enough to serve multiple 3PG projects
– specific enough to allow for a plug-and-play setup for new applications
We have created the following setup:
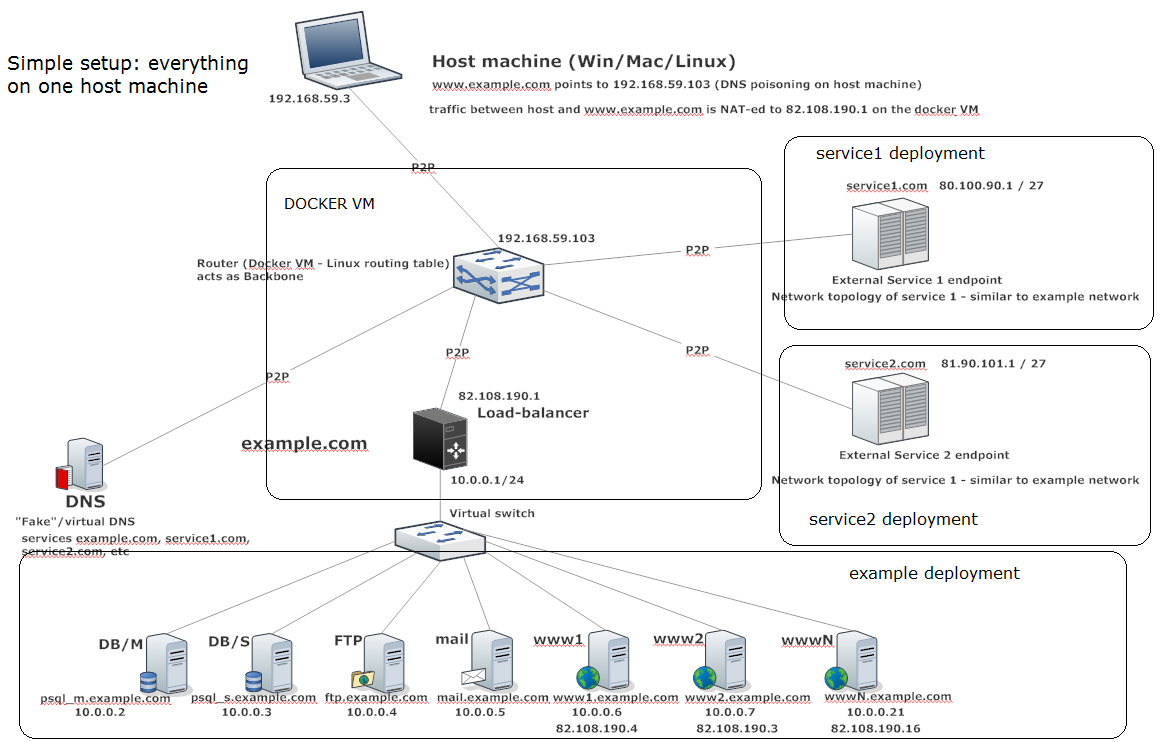
We’ve made a setup where there is a generic domain (example.com) which contains:
– a pre-configured mail server (3pg@example.com already set up)
– a pre-configured ftp server (3pg username already set up)
– a PostgreSQL server, which has a sample DB set up (called ‘skel’ – from skeleton)- contains 2 tables: users and companies pre-populated with some dummy data.
– 2 tomcat servers with 2 pre-installed web applications
– a simple ‘hello world’ jsp page
– a sample ‘skel’ web application which exposes REST endpoints to perform CRUD operations on users and companies; we’re using Spring boot for the back-end and ember.js, ember-data, for REST frontend client
– one load balancer (ha_proxy)
Some networking rules as well as maven configuration make it possible to deploy the ‘skel’ application directly from the host machine; each server is reachable via some ports from the host machine directly:
– www1 is reachable via port 81
– www2 via port 82
– and so on
If stations are accessed via these ports, the load balancer is short-circuited; this is also useful if one wants to interact with a specific web server, instead of passing through the load-balancer.
The application can be then accessed from the host machine to https://www.example.com/skel-0.1.0/
For the URL to work like that, we only need to pollute the local (host machine) DNS:Append the following line:
192.168.59.103 www.example.com
in the /etc/hosts or
c:\windows\system32\drivers\etc\hosts file.
Adding new types of stations
These pre-installed images make it easy for a new Java-based web application to be deployed possibly without even creating a new Docker image; just deploy your application on tomcat 8. In case one wants to deploy another type of application (e.g. python + django + wsgi), one needs to perform these steps:
– create a Dockerfile in its own folder (e.g. django/Dockerfile): maybe directly from the Docker repository
– add any needed files in that folder
– best (but not mandatory) would be to set apomon/base as the base image => one has working ssh (without password for user 3pg), and 3pg username out of the box
– ideally all the servers should be started via the startup.sh script (just add the server you want to start)
– this makes it easier to use our solution of not starting the container if the container has some corrupted files
– this works because if startup.sh fails, the container simply does not start.
– modify the launch script by adding one / multiple containers of that image in the cluster of your choice.
– optional: modify example.com into another domain by editing the dns/hosts file
– optional: modify the network address of example.com and the gateway; by default, all the stations inside a domain can run inside the same network (see the picture above): all stations are linked by a virtual switch (brctl) and have one default gateway (which may also play the role of load-balancer). It is also possible to have the stations inside a domain split into multiple networks: just create as many clusters as network addresses and assign the desired container to the desired cluster. That’s all.
Our networking solution
As you can see, the network topology can be quite complicated. By default we deploy:
– star topology at the cluster level: all the clusters are linked by the backbone container, which assures the OSI layer 3 connectivity between any 2 containers inside any two different clusters.
– star topology at the container level: all the containers inside a cluster are linked by a virtual switch.
This kind of topology is not possible with the linking features provided by Docker. Docker is limited when it comes to creating links between containers; one can define IP ranges for containers and the container receives a random IP from the range (usually IPs from 172.x.y.z range). The whole topology then looks like a big switch (all hosts are linked to docker0 bridge) so:
– it’s harder to implement the desired traffic flow (e.g. for a load-balancer)
– you need manage a separate application configuration
We don’t want that. We want to be able to assign any IP (including public IPs) address on any container and have the same application configuration as the one in production. Our solution to this problem is easy: simply use one of the features Docker is built upon: network namespaces.
We create one network namespace per container (have the same name as the container), and:
– we allocate all the IPs for a container in its own network namespace
– we add the routing table entries for a container in its own network namespace
– we create links when necessary: P2P links between two hosts or simply add existing interfaces in a virtual switch (this one ‘lives’ in the global namespace)
– there is one virtual switch per cluster, and all the containers are linked to it.
Then we use the concept of clusters, which is nothing more than a group of containers which are linked in the same virtual switch and share the same network address, and the same default gateway (which is also part of the cluster); a cluster is thus a LAN with a star topology.
Then, all the clusters are linked by one container which we call the backbone. The backbone links all the clusters together, acting as an edge router. The backbone also links the clusters to the docker VM, making the communication between host machine and containers possible.The backbone also plays the role of the DNS server in our setup.
Some routines were created with the purpose of making the building of the network topology very easy:
start_cluster example example.com apomon/lb 10.0.0.1 10.0.0.0/24 add_container_to_cluster example psql.example.com apomon/psql 10.0.0.6/24 10.0.0.1 add_container_to_cluster example www1.example.com apomon/tomcat 10.0.0.4/24 10.0.0.1add_container_to_cluster example www2.example.com apomon/tomcat 10.0.0.5/24 10.0.0.1 start_cluster service service.com apomon/base 10.0.1.1 10.0.1.0/24 add_container_to_cluster service service_endpoint.service.com apomon/base 10.0.1.2/24 10.0.1.1
This creates two clusters: one with tomcat, load-balancer, psql and another one with a single container.
Integrity check solution
It is useful to check the integrity of certain files in your VE: configuration files are one pertinent example. For that, we provide a simple script which calculates the checksum for the files you want to check and another one which checks the integrity of the files when the container starts, and, if the check fails for at least one of them, the container will simply fail to start and the whole launching operation fails. The script logs the files which have a problem in a log file which is in the root apomon directory.
It is easy and desirable to modify these scripts for your needs. A real-life scenario would imply that the verification file is stored on some HTTP / S3 / FTP location and the verification script takes that file from there before performing the verification.
Not starting the container in case at least one file is corrupt is achieved by making the container run the startup.sh script and by making that script fail in case some file is corrupt. In case startup.sh fails, the container will simply not start.
 The Revenue Cycle Playbook:
The Revenue Cycle Playbook: