June 16, 2016
Understanding Data in Data Science – Multiple Variable Summaries
In my previous post on understanding data for analysis, I described the common approaches for the analysis of single variables. In this post, I’ll summarize the common approaches for analyzing the relationships between multiple variables in your data. Why is an analysis of the relationships important? Let’s start with a paradox.
Simpson’s Paradox
An intriguing effect is sometimes observed when the analysis of single variables leads to a trend that reverses or disappears when the variables are combined or the effect of confounding variables are taken into account. In the fall of 1973 at UC Berkeley, there were allegations of gender bias in the graduate school admissions. It was observed that men had a 44% admission rate against 35% for women, a difference that was unlikely to be caused by a random anomaly.
However, a breakup of the admission rates by all departments revealed that the allegations were not true. The conclusion from the new data was women tended to apply to competitive departments with low rates of admission while men tended to apply to less competitive departments with higher rates of admission. The moral of the story is it is important to analyze the relationships between variables.
Covariance
Covariance is a measure of the tendency of two variables to vary together. Covariance is expressed as:
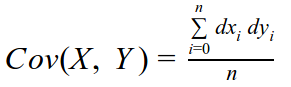
- X, Y are two series
- dxi and dyi are the difference of each data point from the sample mean x and sample mean y
- n is the length of the series samples (both samples must be the same size)
Additionally, Python libraries, such as NumPy, account for corrections from small sample sizes. Covariance is interpreted as:
- If two variables vary together, the Covariance is positive
- If they vary opposite to each other, the Covariance in negative
- If they don’t have an effect on each other, the Covariance is close to zero
Pearson’s Correlation
Covariance is rarely used in summary statistics because it is hard to interpret. By itself, it does not provide a sense of how much the two variables vary together, but only their ‘direction’ (if you consider each series to be a vector). The unit of Covariance is also confusing because it is the product of two different units. Pearson’s Correlation divides the Covariance with the product of the standard deviations of both series resulting in a dimensionless value.
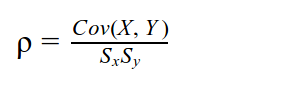
Pearson’s Correlation is bounded in [-1, 1].
- If it is positive, the two variables tend to be high or low together
- If it is negative, the two variables tend to be opposite of each other
- If it is zero or close to zero they don’t affect each other
Sx, Sy are the standard deviations of the X, Y series respectively. Standard Deviation (σ) is a measure of the spread of the distribution.
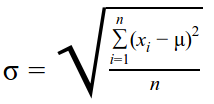{kind=link}
Crosstabs
Crosstabs (short for cross tabulations) are counts of the intersection of two categorical variables (while Covariance and Correlations hold true for continuous variables). For example, if you have two categorical variables – X with values (1, 2, 3) and Y with values (‘A’, ‘B’, ‘C’), a crosstab will be a 3×3 matrix that counts the number of times each value occurs together in the data set.
|
X/Y |
A |
B |
C |
|
1 |
234 |
25728 |
1237 |
|
2 |
26 |
0 |
57 |
|
3 |
13549 |
144 |
4235 |
Crosstabs are suggested only when you suspect a relationship between two categorical variables as the matrices can become large and hard to analyze.
Spearman’s Rank Correlation
Pearson’s Correlation is misleading in the face of non-linear relationships between the variables and if the variables are not normally distributed. It is also susceptible to outliers. Spearman’s Rank Correlation corrects for these effects by computing the Correlation between the ranks of each series. The rank of a value in the series is its index in the sorted list. The computation of the Spearman’s Rank Correlation is more expensive than Pearson’s Correlation because it involves sorting the two series or computing the ranks by index hashing. The formula is the same as Pearson’s correlation, but the series X, Y are the ranks of the values in the original series. This is best explained with a table – follow the colors to see the value to rank transformation:
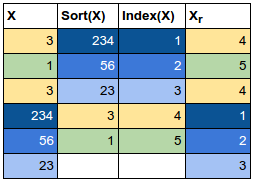
The formula can be expressed as:
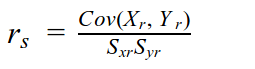
Are we there yet?
We know enough to analyze a wine quality data set, obtained from UC Irvine’s archives. The data set has 11 input variables and one output variable – quality – that was assessed by expert testers. The input variables are: fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulfates, and alcohol.
It helps to have some domain knowledge of the data set as you can use this knowledge to avoid calculating correlations for known relationships and detect spurious correlations as well. This data set, however, is small enough to compute a correlation matrix for all the input variables.
Correlation Matrix
A correlation matrix denotes the correlation coefficients between the input variables. Let’s additionally add a dash of data visualization to the matrix so that we don’t end up staring at numbers. This is called a Correlogram.
I analyzed the input variables and observed that they did not conform to a normal distribution. I also compared the Pearson’s correlation and Spearman’s Rank correlation coefficients for a couple of input variables and found significant differences. Given these observations, I decided to compute the matrix using Spearman’s Rank correlation. Using R:
df <- read.csv("winequality-red.csv", header=TRUE, sep=";")
idf <- df[,1:11]
mcor <- cor(idf, method=c("spearman"))
#install.packages("corrplot")
library(corrplot)
corrplot(mcor, type="upper", order="hclust", tl.col="black", tl.srt=45)
This is what we get:
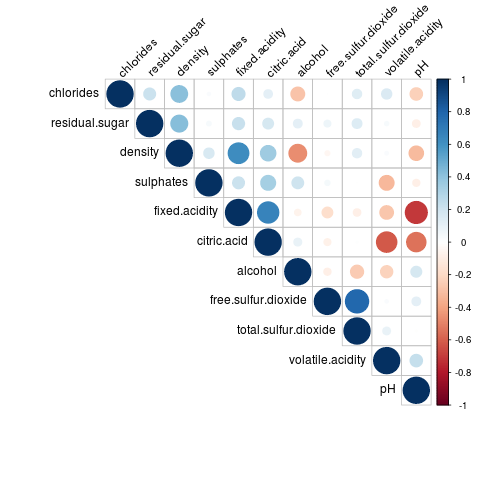
What can we decipher from the Correlogram?
- Fixed acidity and pH are negatively correlated, as is pH and citric acid. This is expected and you can use expectations of such relationships to check the validity of the data.
- Density and alcohol are negatively correlated. Is this a spurious correlation?
- Total and free sulfur dioxide are positively correlated.
Scatter Plots
Scatter Plots are a simple way to visualize the relationship between two (or more) variables. For two dimensions, they plot the location of the data point. The more correlated the variables are, the narrower a band towards which the plot tends. Scatter plots can become confusing when there are a large number of points or outliers ; hexbin plots are used in these cases. A hexbin plot divides the graph into hexagonal bins and colors each bin according to the number of points in each bin.
Let’s draw scatter and hexbin plots for pH versus fixed acidity and Total versus free sulfur dioxide. Using Python:
import pandas as pd
import matplotlib.pyplot as plt
columns = ["fixed acidity", "volatile acidity", "citric acid", "residual sugar", "chlorides", "free sulfur dioxide", "total sulfur dioxide", "density", "pH", "sulphates", "alcohol"]
df = pd.read_csv("winequality-red.csv", sep=";")
df.plot.scatter(x=columns[0], y=columns[8])
df.plot.hexbin(x=columns[0], y=columns[8], gridsize=10)
df.plot.scatter(x=columns[5], y=columns[6])
df.plot.hexbin(x=columns[5], y=columns[6], gridsize=25)
plt.show()
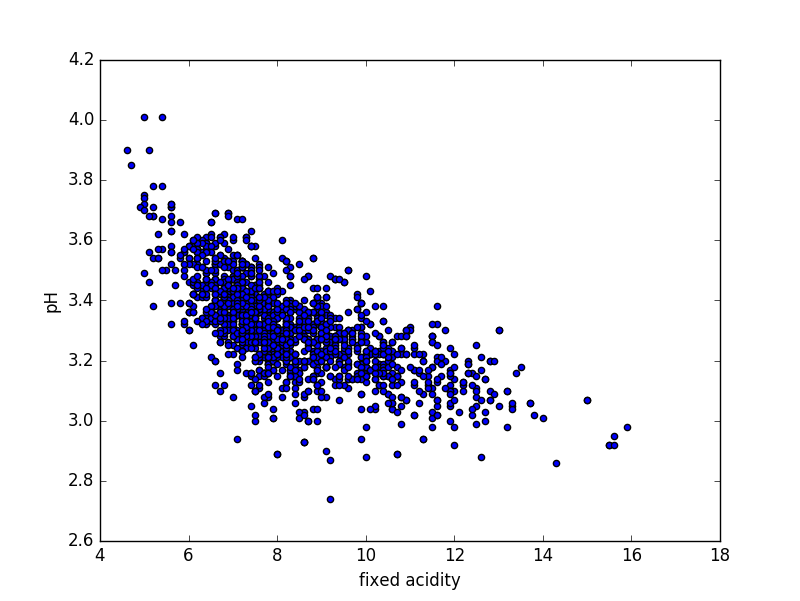
Scatter plot – fixed acidity vs pH
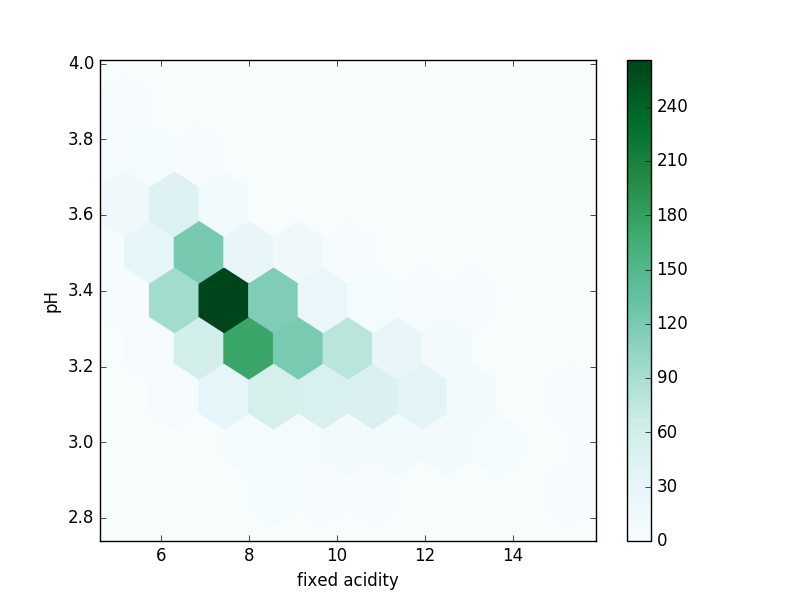
Hexbin plot – fixed acidity vs pH
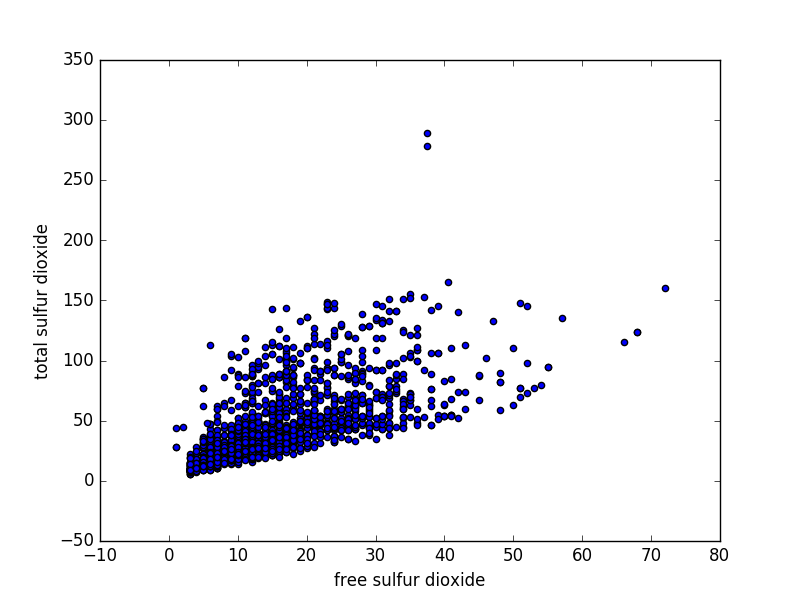
Scatter plot – free vs total sulfur dioxide
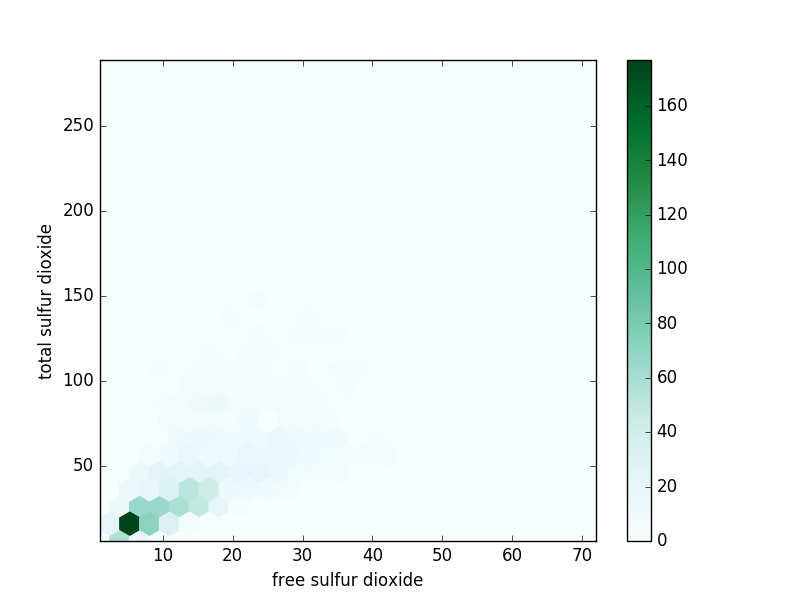
Hexbin plot – free vs total sulfur dioxide
Conclusion
There are a couple of interesting things worth mentioning:
- The Anscombe’s Quartet are datasets that have similar simple summaries but appear very different from each other on a scatter plot. The datasets were created to underline the importance of visualizations for the analysis of data.
- It is tempting to deduce a slope from the scatter plots; however, this can be misleading. The Wikipedia page on correlations has a section on linear, nonlinear input variables and their scatter plots. They show it is possible to have a perfect correlation of 1 or -1, yet have very different slopes.
Single and multiple variable summaries provide you with a starting platform for a data audit strategy. You need to couple this with effective visualizations to understand your data and check for misleading summary statistics.