SQL Server 2014 — Columnstore Indexes Explained
Columnstore indexes were first released with SQL server 2012 and have now gained a shiny new polish with the release of SQL server 2014. MSDN claims an increase of performance of up to 10 times can be gained by using column store indexes. But what are they and how are they better?
Flashback to Non-Columnstore Index
The frequent analogy used for explaining clustered index is a dictionary. In a dictionary, all entries are sorted by name, so if to look-up the meaning of a word, one can just flip directly to that alphabet’s block and find the entry. In this case the data is actually stored sorted. A non-clustered index, on the other hand, can be explained by taking example of a glossary at the back of a book. In the glossary, the topics are listed alphabetically, but once you find the topic name in the glossary, you get the page number of the topic, not the actual content of that topic. You then have to flip to that page to read about that topic. In this case, the data (topics in the book) are not physically sorted alphabetically by topic. But the focus here is on storage.
Pages — Unit of Storage
If we had to make our own SQL server for the above scenarios, the first question would be how to store all the categories, catalogs, books, and contact numbers. Ultimately, all data that is stored on a computer, is stored as bits. This applies to SQL server data and indexes also. SQL server uses 8KB pages to store data, indexes, and other metadata. These pages are then grouped into buckets by SQL server, which are known as Extents. Each extent contains eight contiguous pages, picked from all the pages of the database numbered from 0 to n.
When we define a clustered index with a single partition (default), SQL server creates a B-tree, with each node as a single page. The leaf nodes of this B-tree contain actual data. Every time new data is inserted in the table, that data is adjusted in one of the leaf node pages of the B-tree, based on the sorting. The index itself is updated as well. For a non-clustered index, the leaf nodes contain a pointer to the actual data location. So in a query that uses the index, after the index seek, there is an extra step of getting the actual data from the pointer location. However, in this case, whenever new data is added to the table, only the index is updated, the underlying data is not re-sorted. A rowstore table stored in pages looks like:

Here, every row is stored as a whole and the page contains an array of rows. In case the table is too big to fit in one page, the rows get split over to another page. A columnstore, on the other hand, uses columnar storage and stores a single column in every page:

Back to the Future
So SQL server first divides a table into groups of rows, then stores each rowgroup in the columnar format, with a single column per page. The single column can then be compressed (since columns generally contain similar values for multiple rows), to reduce the input/output operations needed. Also, this can improve performance if the query only frequently needs some columns of the table. The number of pages that need to be read to get the desired data decreases. However, if a select query is fired that fetches all columns, the number of pages accessed would increase. SQL server also stores some rows in rowstore format to improve performance. This temporary rowstore is called deltastore. Both, deltastore and rowgroups and can be checked using system table sys.column_store_row_groups.
Clustered Columnstore Indexes (CCI)
In a clustered columnstore index, the table itself is stored in a columnar format. So by creating a clustered columnstore index on a table, the same compression can be achieved as described above. This means less storage space. Also, with clustered columnstore indexes, there is no physical sorting of data. In SQL Server 2014, this index is updatable. Still, even with a CCI, the rows of a table are not immediately compressed when added. As an example, a if new table is created using the following sample script:
CREATE TABLE [dbo].[Employee]( [EmpId] [int] IDENTITY(1,1) NOT NULL, [EmpName] [varchar](250) NOT NULL, [DepartmentId] [int] NOT NULL, [SkillsMappingId] [int] NULL, [DateOfJoining] [date] NOT NULL, [DateLeft] [date] NULL ) ON [PRIMARY]
And then one row is added to this table without creating any indexes:
INSERT INTO [dbo].[Employee]
([EmpName]
,[DepartmentId]
,[SkillsMappingId]
,[DateOfJoining]
,[DateLeft])
VALUES
('John'
,1
,1
,'1/1/2014'
,null)
Suppose now a CCI is created on this table as:
CREATE CLUSTERED COLUMNSTORE INDEX [CCI_Employee] ON [dbo].[Employee] WITH (DROP_EXISTING = OFF)
If the sys.column_store_row_groups table is checked, it would contain the following:
select * from sys.column_store_row_groups where object_id =OBJECT_ID('Employee')
![]()
This shows that all data added to the Employee table was compressed in a single rowgroup, whose size is 480 bytes, and it contains one row. Now, if a new row is added to the table:
INSERT INTO [dbo].[Employee]
([EmpName]
,[DepartmentId]
,[SkillsMappingId]
,[DateOfJoining]
,[DateLeft])
VALUES
('Jack'
,1
,9
,'1/2/2014'
,null)
And again sys.column_store_row_groups table is checked:
![]()
This shows that the new row was added to a new rowgroup, which is right now in the OPEN state (accepting more records) and thus, has not yet been compressed. If we try adding more records, the new rows keep getting added to the rowgroup in the OPEN state and no compression takes place:
INSERT INTO [dbo].[Employee]
([EmpName]
,[DepartmentId]
,[SkillsMappingId]
,[DateOfJoining]
,[DateLeft])
VALUES
('Blake'
,1
,9
,'1/3/2014'
,null)
![]()
Added more rows through the loop:

The rowgroup Id 1 will remain in OPEN state till it is full and is compressed by the tuple mover. We can manually rebuild the index to force compression by running the following script:
DBCC DBREINDEX('dbo.Employee', CCI_Employee);

Now, all rows are compressed in a single rowgroups with size 1513360 bytes.
Non-Clustered Columnstore Indexes
Non-clustered columnstore indexes create a read-only copy of selected columns of the underlying table and can include all columns of the table. This index is generally used for read-only queries. The drawback of using non-clustered columnstore indexes is that the underlying table becomes read-only. So any data changes in the table give the following message:
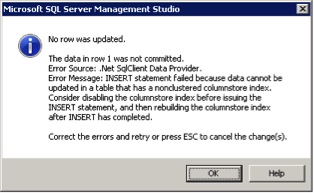
Non-clustered columnstore index is still not updateable in SQL server 2014.
In the End
Though columnstore indexes can compress data to improve performance and also work faster when only few columns in a large dataset need to be fetched, they also come with certain limitations. For some scenarios, the deltastore, compression, and decompression can actually add an overhead. Columnstore indexes do not work well with outer join, not in conditions, union all etc. on the columns of the table with a columnstore index. These indexes work best with queries that support batch processing of data. For other queries also, performance may be better due to reduced I/O. So, as with any other question related to SQL server performance tuning, this question of whether to use columnstore indexes or not can also be answered by saying “it depends”. However, it is important to understand how these indexes work internally to be able to make the right decision. In this blog, I have covered the basics of how columnstore indexes work internally. Please feel free to add your questions, comments, and suggestions below on any of the points covered above.
Recent blog posts




Stay in Touch
Keep your competitive edge – subscribe to our newsletter for updates on emerging software engineering, data and AI, and cloud technology trends.