High Availability and Automatic Failover in Hadoop
Hadoop in Brief
Hadoop is one of the most popular sets of big data processing technologies/frameworks in use today. From Adobe and eBay to Facebook and Hulu, Hadoop is used by a wide range of companies for everything from machine learning and natural language processing to data analysis and ad optimization. It is now a common definition of Hadoop that it caters to “the 3 V’s” – volume, velocity, and variety. With use cases in analytics, search, log processing, analysis, and recommendation engines, Hadoop is commonly used in applications that are data-intensive.
The Hadoop Distributed File System (HDFS) is a reliable Hadoop shared storage. It scales horizontally, which means we can add as many nodes/servers without shutting down the system, which with commodity hardware can be very cost effective. It can be used to process both structured as well as unstructured data. It is highly optimized for very large sets of data.
The Hadoop Landscape
According to Forbes, 53% of companies in one recent study were employing big data analytics, which was “defined as systems that enable end-user access to and analysis of data contained and managed within the Hadoop ecosystem.” For a list of companies that use Hadoop and short descriptions of how they use it, see this Powered By page on the Hadoop Wiki.
Problems with the Hadoop Framework
Prior to Hadoop 2.0, i.e. Hadoop 1.0, there was a single point of failure (SPOF) in NameNode. By this, we mean if the NameNode fails, then whole Hadoop system/Cluster goes down. Then it can only be recovered manually with the help of a secondary NameNode which results in overall downtime of the Hadoop Cluster, i.e. the Hadoop cluster would not be available unless the Hadoop administrator restarts the NameNode.
Solution for SPOF
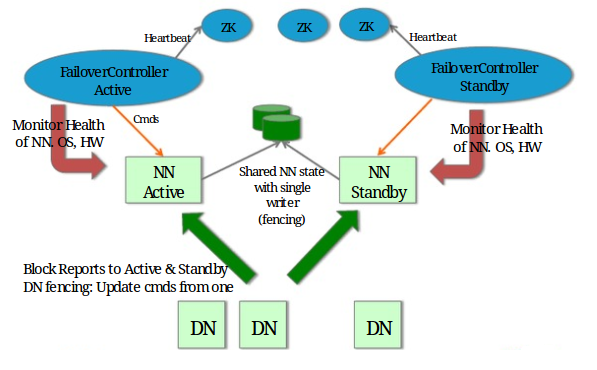
The shortcoming in Hadoop 1.0 was overcome in Hadoop 2.0 by providing support for two NameNodes. It introduces the Hadoop 2.0 High Availability feature that brings in an extra NameNode (Passive Standby NameNode) to the Hadoop Architecture, which is configured for automatic failover. Now Hadoop has its built-in fault tolerance. Data is replicated across multiple nodes by means of replication factor, which can be configured at the admin end and if a node (Active NameNode) goes down, the required data can be read from another node (Standby NameNode), which has the copy of that data by courtesy of Journal nodes.
Why/How can NameNode go down?
- Suppose you gave your cluster to another developer who did not understand the performance issues and ran a simple directory traversal, which gave a massive load to NameNode such that it crashed, hence the entire cluster goes down.
- If someone is trying to process a large number of small files, Hadoop performance can get a hit and NameNode can go down.
- Latency spikes due to garbage collection on the NameNode can bring NameNode down.
- If the root partition ran out of space, NameNode can crash with a corrupted edit log.
- It’s often a requirement that HDFS requires commercial NAS to which the NameNode can write a copy of its edit log. The entire cluster goes down any time the NAS is down because the NameNode needs to hard-mount the NAS.
Enabling High Availability and Automatic Failover
If you are running Hadoop and want to ensure stability and reliability of your cluster, one can overcome it by facilitating Hadoop’s high availability and automatic failover options. The problem this addresses is that without using high availability and automatic failover, any time the NameNode goes down, the entire system goes down. You can think of high availability and automatic failover as your insurance policy against a single point of failure.
Approx Downtime during Automatic Failover
As per Hortonworks:
- A 60 node cluster with 6 million blocks using 300TB raw storage, and 100K files: 30 seconds. Hence total failover time ranges from 1-3 minutes.
- A 200 node cluster with 20 million blocks occupying 1PB raw storage and 1 million files: 110 seconds. Hence total failover time ranges from 2.5 to 4.5 minutes.
Is automatic failover more expensive then SPOF?
Split-brain scenario
Besides a small downtime using HA, the other important point to be noted is that it is important for an HA cluster that only one of the NameNodes is active at a time. Otherwise, the namespace state would be divided between the two, risking data loss or other incorrect results. In order to ensure this property and prevent the so-called “split-brain scenario”.
In this case, multiple master nodes think they’re in charge of the cluster, is a “time skew” on the order of perhaps 10 or more seconds between the current master node and the other master. This is however taken care by JournalNodes, they will only allow a single NameNode to be a writer at a time. During a failover, the Standby NameNode which is to become active will play the role of writing to the JournalNodes, and prevent the other NameNode from continuing in the Active state, allowing the new Active NameNode to successfully take the failover
The video tutorial
This video tutorial was created for Hadoop administrators or database administrators responsible for administering their company’s Hadoop clusters. It assumes intermediate knowledge of Hadoop and provides a step-by-step walkthrough of how to enable high availability and automatic failover using Zookeeper.
Configuration details after HA implementation
The following changes are made in the files after implementing HA in Hadoop cluster:
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://nameservice1</value>
</property>
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>nameservice1</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.nameservice1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.nameservice1</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>qa-us1-dh-db031.domain.com:2181,qa-us1-dh-db032.domain.com:2181,qa-us1dhub050.blackarrow-corp.com:2181</value>
</property>
Conclusion
Automatic Failover in Hadoop starts automatically in case of NameNode crashdown. Automatic failover adds ZooKeeper quorum and ZKFailoverController Process (ZKFC) components to an HDFS deployment. Work is going on to make Automatic failover a better process, like without starting the HDFS service and to reduce the HA time.
As per Cloudera, work was recently started to allow Hadoop configuration changes without a restart.
https://issues.apache.org/jira/browse/HADOOP-7001
https://issues.apache.org/jira/browse/HDFS-1064
A number of changes (eg HDFS-1070, HDFS-1295, and HDFS-1391) are under way to significantly improve the time it takes to restart HDFS.




Stay in Touch
Keep your competitive edge – subscribe to our newsletter for updates on emerging software engineering, data and AI, and cloud technology trends.