How Web Caching Improves Internet Performance
The internet is a system with huge distributed information that provides access to shared data objects. In recent years, there has been exponential growth in the size of the internet, which causes network congestion. There are discrete natures of the internet documents that can help everyone find information according to their liking. However, this huge rate of growth has put a heavy load on the internet communication channels.
As the internet has grown in both vogue and size, so have the scalability demands on its infrastructure. Expanding growth without solutions will finally result in more network load and unacceptable service response times. These are the reasons why web users are suffering from network congestion and server overloading. Web users’ bad experience with internet performance increase the demands on the web’s infrastructure.
It is well-known that the main reason for the increase in web traffic, specifically HTTP traffic, is due to the rise in popularity of the web. Caching and web pre-fetching of user details attempts to improve the performance of the internet in many ways.
First, caching attempts to reduce the latency of the user associated with obtaining web documents. Latency can be reduced because the cache is naturally much nearer to the client than the provider of the content.
Second, caching tries to reduce the network traffic from the internet servers. Network load can be reduced because pages that are served from the cache have to traverse less of the network than when they are served by the provider of the content.
Finally, caching can reduce the number of requests on the content provider. It also may lower the transit costs for access providers.
As the name suggests, web pre-fetching is the fetching of web pages in advance by a proxy server or client before any request is send by a client or proxy server. A major advantage of using web pre-fetching is that there is less traffic and a reduction in latency. When a request comes from the client for a web object, rather than sending request to the web server directly, the request can be fetched from the pre-fetched data.
The main factor for selecting a web pre-fetching algorithm is its ability to predict web objects to be pre-fetched in order to reduce latency. Web pre-fetching exploits the spatial locality of webpages, meaning pages that are linked with the current webpage and will have a higher probability of use than the other webpages. Web pre-fetching can be applied in a web environment between clients and a web server, as well as in between proxy servers and a web server and between clients and a proxy server. If pre-fetching is applied between clients and web server, it is helpful in decreasing user latency; however, it will increases network traffic. If it is applied between a proxy server and a web server, then it can reduce the bandwidth usage by pre-fetching only a specific number of hyperlinks. If it is applied between clients and a proxy server, then the proxy will begin feeding pre-fetched web objects from the cache to the clients so that there won’t be extra internet traffic.
Advantages of Caching
Webpages can be cached pre-fetched on the clients, the proxies, and the servers. There are many advantages of web caching, including an improved performance of the web.
- Caching reduces bandwidth consumption; therefore, it decreases network traffic and diminishes network congestion
- Caching reduces access latency for two reasons:
a) Frequently accessed documents are fetched from a nearby proxy cache instead of remote data servers; therefore, the transmission delay is minimized.
b) Caching can reduce the network traffic, so those documents that are not cached can also be retrieved comparatively faster than without caching due to less congestion along the path and with less work load on the server. - Caching reduces the workload of the remote web server by spreading the data widely among the proxy caches over the WAN.
- In a scenario where the remote server is not available due to a crash or network partitioning, the client can obtain a cached copy at the proxy. Hence, the robustness of the Web service is enhanced.
Disadvantages of Caching
- The major disadvantage of caching is that a client might be looking at stale data, which can happen because of a lack of proper proxy updating.
- The access latency may rise, in the case of a cache miss, due to some extra proxy processing. Therefore, while designing a cache system, the cache hit rate should be maximized and the cost of a cache miss should be minimized.
- A single proxy cache is always a bottleneck. Some limit has to be set for the number of clients a proxy can serve.
- A single proxy is a single point of failure.
- By implementing a proxy cache, we can reduce the hits on the original remote server. This may disappoint many information providers because they won’t be able to maintain a true log of the hits to their pages. In this case, they might decide to not allow their documents to be cached.
Proxy Caching
Proxy servers are generally used to allow users access to the internet within any firewall. For security reasons, companies run a special type of HTTP server called “proxy” on their own firewall machines. A proxy server usually processes requests from within a firewall by forwarding them to the remote servers, intercepting the responses in between, and sending the replies back to clients. Because the same proxy servers are shared by all clients inside of the firewall, this naturally leads to the question of the effectiveness of using the proxy to cache documents. The clients within the same firewall usually belong to the same organization and likely share some common interests, so there’s a high probability that they would access the same set of documents and each client might have the tendency to browse back and forth within a short period of time. So on the proxy server, a previously requested and cached document would likely result in future hits by user. Web caching at a proxy server can not only save the network bandwidth, but can also lower the access latency for the clients.
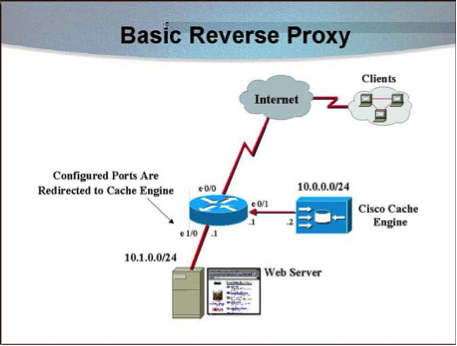
Reverse Proxy Caching
An interesting twist to the proxy cache approach is the notion of reverse proxy caching, where caches are deployed not to near clients but on the origin of the content. This is an attractive solution for the servers that expect a high number of requests and want to ensure a high level of service quality. Reverse proxy caching is a useful mechanism when supporting web hosting farms, or virtual domains mapped to a single physical site, which is an increasingly common service for many Internet service providers (ISPs).
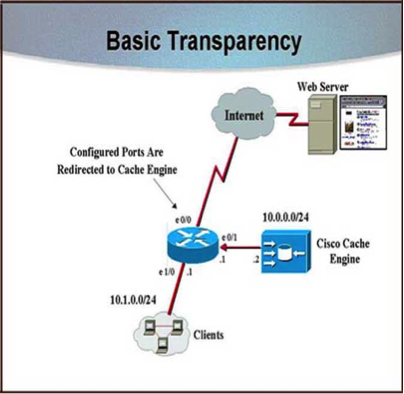
Transparent Caching
Transparent proxy caching removes one of the big drawbacks of the proxy server approach: the requirement that configures web browsers. Transparent caches work by obstructing HTTP requests and redirecting them to web cache clusters or cache servers. This caching style establishes a point at which different kinds of administrative controls are possible; for example, to judge how to load balance requests from the multiple caches. There are two ways to deploy transparent proxy caching: the first at the switch level and the second one at the router level.
Router-based proxy caching uses policy-based routing to direct requests to their appropriate cache(s). This means that requests from certain clients can be associated by a particular cache.
In switch-based transparent proxy caching, switch acts as a dedicated load balancer. This approach is attractive because it decreases the overhead and is usually incurred by policy-based routing. Since switches are generally less expensive than routers, it reduces cost to the deployment.
Caching Architectures
Hierarchical Caching Services
We can set up a caching hierarchy as an approach to coordinate caches in the same system. There are multiple levels of networks where a cache is kept. For the sake of clarity, we will assume that there are four levels of caches:
- Bottom
- Institutional
- Regional
- National
We have client/browser caches at the bottom level. When there is a request made of a web page and it is not fulfilled by the client cache, the request is forwarded to the institutional cache. If the page is not found at the institutional level, then we redirect the request to the next level in the hierarchy – the regional level. In the regional level cache server, the request checks whether or not a webpage is there. If the webpage is there with the cache, then it serves the request with the content; otherwise, it forwards the cache to the next level – the national level. When the request reaches the national level from the regional level, it cheeks its cache for the web document content. If the content is there, it is returned; otherwise, it communicates with the original server to get the latest content and then the request is served. The copy of the original request is kept with the each level of the cache in the hierarchy, so if the same request comes again then it gets served from the cache itself.
Distributed Caching Architecture
As the name suggests, distributed caching is a caching architecture in which we do not have different cache servers; instead, we have only one cache level known as the institutional cache. There is different institutional level distributed in the server. These cache levels know information about each other to serve requests. All the meta-data information of the content of each institutional cache level is kept within each institutional cache level to serve the requests. In distributed caching, the traffic mainly flows via low network levels, which are less congested. With distributed caching, we can achieve better load sharing and fault tolerant. However, there can be many problems, such as higher bandwidth usage and admin issues, due to a huge deployment of distributed caching.
There are mainly two approaches in which distributed caching can be achieved:
- Internet Cache Protocol (ICP): In ICP, we support the discovery and retrieval of web pages from different neighboring caches, as well as their parent caches.
- Cache Array Routing Protocol (CARP): In this technique, the space of the URL is divided between arrays of loosely coupled caches and lets each cache store only the documents whose URLs are hashed to it.
Recent blog posts




Stay in Touch
Keep your competitive edge – subscribe to our newsletter for updates on emerging software engineering, data and AI, and cloud technology trends.