How to Analyze Big Data with Hadoop Technologies
With rapid innovations, frequent evolutions of technologies and a rapidly growing internet population, systems and enterprises are generating huge amounts of data to the tune of terabytes and even petabytes of information. Since data is being generated in very huge volumes with great velocity in all multi-structured formats like images, videos, weblogs, sensor data, etc. from all different sources, there is a huge demand to efficiently store, process and analyze this large amount of data to make it usable.
Hadoop is undoubtedly the preferred choice for such a requirement due to its key characteristics of being reliable, flexible, economical, and a scalable solution. While Hadoop provides the ability to store this large scale data on HDFS (Hadoop Distributed File System), there are multiple solutions available in the market for analyzing this huge data like MapReduce, Pig and Hive. With the advancements of these different data analysis technologies to analyze the big data, there are many different school of thoughts about which Hadoop data analysis technology should be used when and which could be efficient.
A well-executed big data analysis provides the possibility to uncover hidden markets, discover unfulfilled customer demands and cost reduction opportunities and drive game-changing, significant improvements in everything from telecommunication efficiencies and surgical or medical treatments, to social media campaigns and related digital marketing promotions.
What is Big Data Analysis?
Big data is mostly generated from social media websites, sensors, devices, video/audio, networks, log files and web, and much of it is generated in real time and on a very large scale. Big data analytics is the process of examining this large amount of different data types, or big data, in an effort to uncover hidden patterns, unknown correlations and other useful information.

Advantages of Big Data Analysis
Big data analysis allows market analysts, researchers and business users to develop deep insights from the available data, resulting in numerous business advantages. Business users are able to make a precise analysis of the data and the key early indicators from this analysis can mean fortunes for the business. Some of the exemplary use cases are as follows:
- Whenever users browse travel portals, shopping sites, search flights, hotels or add a particular item into their cart, then Ad Targeting companies can analyze this wide variety of data and activities and can provide better recommendations to the user regarding offers, discounts and deals based on the user browsing history and product history.
- In the telecommunications space, if customers are moving from one service provider to another service provider, then by analyzing huge call data records of the various issues faced by the customers can be unearthed. Issues could be as wide-ranging as a significant increase in the call drops or some network congestion problems. Based on analyzing these issues, it can be identified if a telecom company needs to place a new tower in a particular urban area or if they need to revive the marketing strategy for a particular region as a new player has come up there. That way customer churn can be proactively minimized.
Case Study – Stock market data
Now let’s look at a case study for analyzing stock market data. We will evaluate various big data technologies to analyze this stock market data from a sample ‘New York Stock Exchange’ dataset and calculate the covariance for this stock data and aim to solve both storage and processing problems related to a huge volume of data.
Covariance is a financial term that represents the degree or amount that two stocks or financial instruments move together or apart from each other. With covariance, investors have the opportunity to seek out different investment options based upon their respective risk profile. It is a statistical measure of how one investment moves in relation to the other.
A positive covariance means that asset returns moved together. If investment instruments or stocks tend to be up or down during the same time periods, they have positive covariance.
A negative covariance means returns move inversely. If one investment instrument tends to be up while the other is down, they have negative covariance.
This will help a stock broker in recommending the stocks to his customers.
Dataset: The sample dataset provided is a comma separated file (CSV) named ‘NYSE_daily_prices_Q.csv’ that contains the stock information such as daily quotes, Stock opening price, Stock highest price, etc. on the New York Stock Exchange.
The dataset provided is just a sample small dataset having around 3500 records, but in the real production environment there could be huge stock data running into GBs or TBs. So our solution must be supported in a real production environment.
Hadoop Data Analysis Technologies
Let’s have a look at the existing open source Hadoop data analysis technologies to analyze the huge stock data being generated very frequently.

Features and Comparison of Big Data Analysis Technologies
| Featured | MapReduce | Pig | Hive |
| Language | Algorithm of Map and Reduce Functions (Can be implemented in C, Python, Java) | PigLatin (Scripting Language) | SQL-like |
| Schemas/Types | No | Yes (implicit) | Yes(explicit) |
| Partitions | No | No | Yes |
| Server | No | No | Optional (Thrift) |
| Lines of code | More lines of code | Fewer (Around 10 lines of PIG = 200 lines of Java) |
Fewer than MapReduce and Pig due to SQL Like nature |
| Development Time | More development effort | Rapid development | Rapid development |
| Abstraction | Lower level of abstraction (Rigid Procedural Structure) | Higher level of abstraction (Scripts) | Higher level of abstraction (SQL like) |
| Joins | Hard to achieve join functionality | Joins can be easily written | Easy for joins |
| Structured vs Semi-Structured Vs Unstructured data | Can handle all these kind of data types | Works on all these kind of data types | Deal mostly with structured and semi-structured data |
| Complex business logic | More control for writing complex business logic | Less control for writing complex business logic | Less control for writing complex business logic |
| Performance | Fully tuned MapReduce program would be faster than Pig/Hive | Slower than fully tuned MapReduce program, but faster than badly written MapReduce code | Slower than fully tuned MapReduce program, but faster than bad written MapReduce code |
Which Data Analysis Technologies should be used?
Based on the available sample dataset, it is having following properties:
- Data is having structured format
- It would require joins to calculate Stock Covariance
- It could be organized into schema
- In real environment, data size would be too much
Based on these criteria and comparing with the above analysis of features of these technologies, we can conclude:
- If we use MapReduce, then complex business logic needs to be written to handle the joins. We would have to think from map and reduce perspective and which particular code snippet will go into map and which one will go into reduce side. A lot of development effort needs to go into deciding how map and reduce joins will take place. We would not be able to map the data into schema format and all efforts need to be handled programmatically.
- If we are going to use Pig, then we would not be able to partition the data, which can be used for sample processing from a subset of data by a particular stock symbol or particular date or month. In addition to that Pig is more like a scripting language which is more suitable for prototyping and rapidly developing MapReduce based jobs. It also doesn’t provide the facility to map our data into an explicit schema format that seems more suitable for this case study.
- Hive not only provides a familiar programming model for people who know SQL, it also eliminates lots of boilerplate and sometimes tricky coding that we would have to do in MapReduce programming. If we apply Hive to analyze the stock data, then we would be able to leverage the SQL capabilities of Hive-QL as well as data can be managed in a particular schema. It will also reduce the development time as well and can manage joins between stock data also using Hive-QL which is of course pretty difficult in MapReduce. Hive also has its thrift servers, by which we can submit our Hive queries from anywhere to the Hive server, which in turn executes them. Hive SQL queries are being converted into map reduce jobs by Hive compiler, leaving programmers to think beyond complex programming and provides opportunity to focus on business problem.
So based on the above discussion, Hive seems the perfect choice for the aforementioned case study.
Problem Solution with Hive
Apache Hive is a data warehousing package built on top of Hadoop for providing data summarization, query and analysis. The query language being used by Hive is called Hive-QL and is very similar to SQL.
Since we are now done zeroing in on the data analysis technology part, now it’s time to get your feet wet with deriving solutions for the mentioned case study.
- Hive Configuration on Cloudera
Follow the steps mentioned in my previous blog How to Configure Hive On Cloudera:
- Create Hive Table
Use ‘create table’ Hive command to create the Hive table for our provided csv dataset:
hive> create table NYSE (exchange String,stock_symbol String,stock_date String,stock_price_open double, stock_price_high double, stock_price_low double, stock_price_close double, stock_volume double, stock_price_adj_close double) row format delimited fields terminated by ‘,’;
This will create a Hive table named ‘NYSE’ in which rows would be delimited and row fields will be terminated by commas. This schema will be created into the embedded derby database as configured into the Hive setup. By default, Hive stores metadata in an embedded Apache Derby database, but can be configured for other databases like MySQL, SQL server, Oracle, etc.
- Load CSV Data into Hive Table
Use the following Hive command to load the CSV data file into Hive table:
hive> load data local inpath ‘/home/cloudera/NYSE_daily_prices_Q.csv’ into table NYSE;
This will load the dataset from the mentioned location to the Hive table ‘NYSE’ as created above but all this dataset will be stored into the Hive-controlled file system namespace on HDFS, so that it could be batch processed further by MapReduce jobs or Hive queries.
- Calculate the Covariance
We can calculate the Covariance for the provided stock dataset for the inputted year as below using the Hive select query:
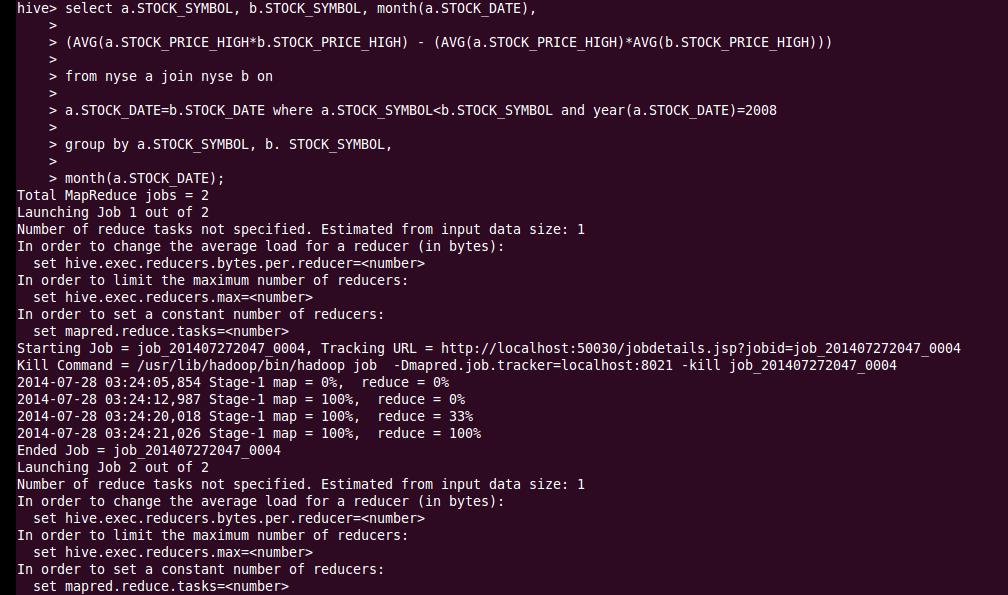
select a.STOCK_SYMBOL, b.STOCK_SYMBOL, month(a.STOCK_DATE),
(AVG(a.STOCK_PRICE_HIGH*b.STOCK_PRICE_HIGH) – (AVG(a.STOCK_PRICE_HIGH)*AVG(b.STOCK_PRICE_HIGH)))
from NYSE a join NYSE b on
a.STOCK_DATE=b.STOCK_DATE where a.STOCK_SYMBOL<b.STOCK_SYMBOL and year(a.STOCK_DATE)=2008
Group by a.STOCK_SYMBOL, b. STOCK_SYMBOL, month(a.STOCK_DATE);
This Hive select query will trigger the MapReduce job as below:
The covariance results after the above stock data analysis, are as follows:
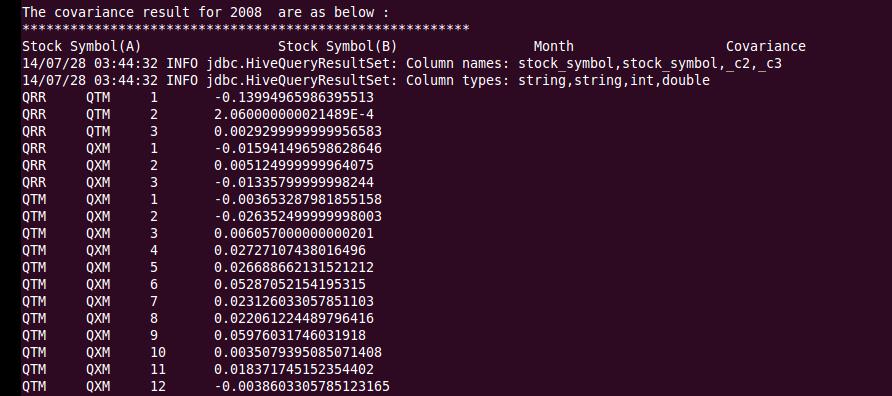
The covariance has been calculated between two different stocks for each month on a particular date for the available year.
From the covariance results, stock brokers or fund managers can provide below recommendations:
- For Stocks QRR and QTM, these are having more positive covariance than negative covariance, so having high probability that stocks will move together in same direction.
- For Stocks QRR and QXM, these are mostly having negative covariance. So there exists a greater probability of stock prices moving in an inverse direction.
- For Stocks QTM and QXM, these are mostly having positive covariance for most of all months, so these tend to move in the same direction most of the times.
So similarly we can analyze more use cases of big data and can explore all possible solutions to solve that use case and then by the comparison chart, the final best solution can be narrowed down.
Conclusion/Benefits
So this case study solves the following two important goals of big data technologies:
- Storage
By storing the huge stock data into HDFS, the solution provided is much more robust, reliable, economical, and scalable. Whenever data size is increasing, you can just add some more nodes, configure into Hadoop and that’s all. If sometime any node is down, then even other nodes are ready to handle the responsibility due to data replication.
By managing the Hive schema into embedded database or any other standard SQL database, we are able to utilize the power of SQL as well.
- Processing
Since Hive schema is created on a standard SQL database, you get the advantage of running SQL queries on the huge dataset also and are able to process GBs or TBs of data with simple SQL queries. Since actual data resides into HDFS, so these Hive SQL queries are being converted into MapReduce jobs and these parallelized map reduce jobs process these huge volume of data and achieve scalable and fault tolerant solutions.
Recent blog posts


Stay in Touch
Keep your competitive edge – subscribe to our newsletter for updates on emerging software engineering, data and AI, and cloud technology trends.