Advantages of Elastic Search
In the recent past, we had a requirement where we needed to get the data analytics for our site. We had our site deployed to various environments for different clients and we had to extract useful data, such as the users who had logged in on a certain day, or the volume of users in different locales, so that our marketing team could create and adjust their strategies accordingly. We explored various approaches, and settled on the Elastic Search data store, which is a free and open source. It’s very easy to use, as it provides the most powerful capabilities for text search because it’s built on top of Lucene.
We had the challenge to get the data analytics from different environments, so we created a scenario where a user has dashboard that they can update to add different charts/graphs at runtime, which provides them with different types of data. For example, the user can search for the active/inactive/logged-in user count or any other type of count from the system by simply changing the type from user interface and then the data should be readily available.
Also, the user should also be allowed to write their own questions, and that data should also be indexed in the database so the user can see the question result in the form of a graph on their dashboard. Elastic Search makes this possible by allowing us to create indexes at runtime, as well as allowing dynamic search and full text search that is well-suited to our needs.
Elastic search was first released in February 2010, and is a free and open source distributed inverted index created by Shay Banon. It is developed in Java, so it is a cross-platform.
Major Highlights of Elastic Search
Built on top of Lucene
Elastic Search is built on top of Lucene, which is a full-featured information retrieval library, so it provides the most powerful full-text search capabilities of any open source product.
Document-Oriented
Elastic Search is document-oriented. It stores real world complex entities as structured JSON documents and indexes all fields by default, with a higher performance result.
Full-Text Search
Elastic Search implements a lot of features, such as customized splitting text into words, customized stemming, facetted search, and more.
Schema Free
Elastic Search is schema free—instead, it accepts JSON documents, as well as tries to detect the data structure, index the data, and make it searchable.
Restful API
Elastic Search is API driven; actions can be performed using a simple Restful API.
Per-Operation Persistence
Elastic Search records any changes made in transactions logs on multiple nodes in the cluster to minimize the chance of data loss.
There are some use cases where Elastic Search is well-suited for performance:
- Searching a large number of products for the best match with a specific phrase
- Auto-completing a search box on partially-typed words, which are based on previous searches.
- Accounting for misspellings in searches
- Storing a large quantity of semi-structured (JSON) data in a distributed fashion
Elastic Search is generally fantastic at providing approximate answers from data, such as scoring the results by quality. Finding approximate answers is a property that separates elastic Search from more traditional databases.
Elastic Search has been adopted by some major logos, including the following:

Basic Concepts
Cluster: A cluster is a collection of nodes that hold data. It provides indexing and search capabilities across all nodes and is identified by a unique name.
Node: A node is a single server that is part of the cluster, stores the data, and participates in the cluster’s indexing and search capabilities.
Index: An index is a collection of documents with similar characteristics, such as customer data or order data. It’s like a relational database, with mappings that define multiple types.
Type: There can be multiple types within an index. For example, in our application we have the GetCount index, which has different sections like active user count and inactive user count.
Document: A document is a basic unit of information that can be indexed. It is like a row in a table in a relational database, such as data for a customer or product, and is described in JSON format. We can have multiple documents in an index, but they must be indexed to a type inside of an index.
Shards and Replicas: An index can potentially store a large amount of data exceeding hardware limits. Elastic Search provides the ability to divide indexes into multiple pieces called shards, which allows the content to scale horizontally. Elastic Search also allows users to make copies of index shards, which are called replicas.
Installation
You can easily download Elastic Search through the following link: https://www.elastic.co/downloads/elasticsearch
Once Elastic Search is installed, you need to add it to your .Net code. You can do this easily through Package Manager Console
Install-Package Elasticsearch.Net

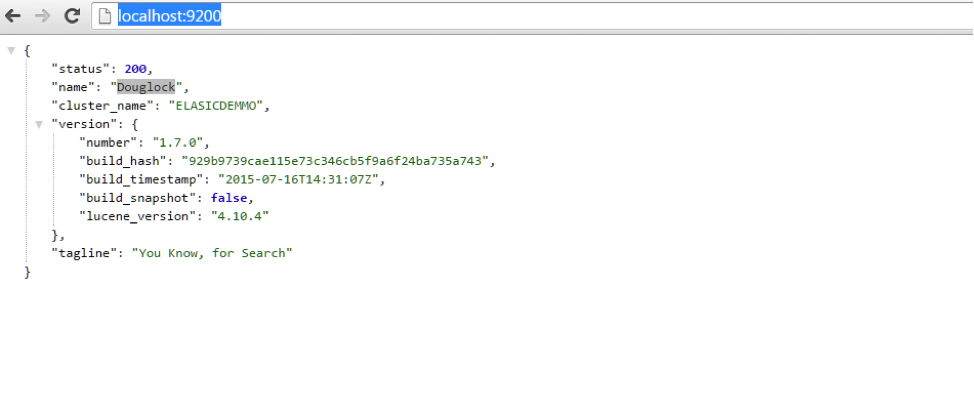
After adding it to your code, you can easily check if Elastic Search is running on your system through the following URL: http://localhost:9200/
Getting Started
To explain the basic operations of Elastic Search, we’ll use the example of our blog class, given below:
public class Blog
{
public string Title { get; set; }
public string User { get; set; }
public string Comment { get; set; }
public string Id { get; set; }
}
Let’s start with creating an Elastic Search client instance.
ElasticsearchClient _ESClient = new ElasticsearchClient(new ConnectionConfiguration(new Uri("http://localhost:9200")));
Elastic Search runs on localhost:9200 by default, so we have created an instance by passing the URL. Now we can add as many indexes as we want with this Elastic Search client object.
We have created a function to add an index with a unique name and type. We added a unique name so that it will be easy to find when the daily scheduled job logs data, and we have defined the type as blog, which is equivalent to a table in a relational database.
public static bool AddtoIndex(Blog blogData)
{
string strIndexName = "MyIndex" + DateTime.Now.ToUniversalTime().ToString("yyyy.MM.dd");
string indexType = "Blog";
var blog = new Blog();
blog.Id = Guid.NewGuid().ToString();
blog.User = blogData.User;
blog.Title = blogData.Title;
blog.Comment = blogData.Comment;
var data = JsonConvert.SerializeObject(blog);
var response = _ESClient.Index(strIndexName.ToLower(), indexType, data);
return response.Success;
}
Now let’s check if an index has been created by using this link: http://localhost:9200/myindex2015.12.01/_search?blog
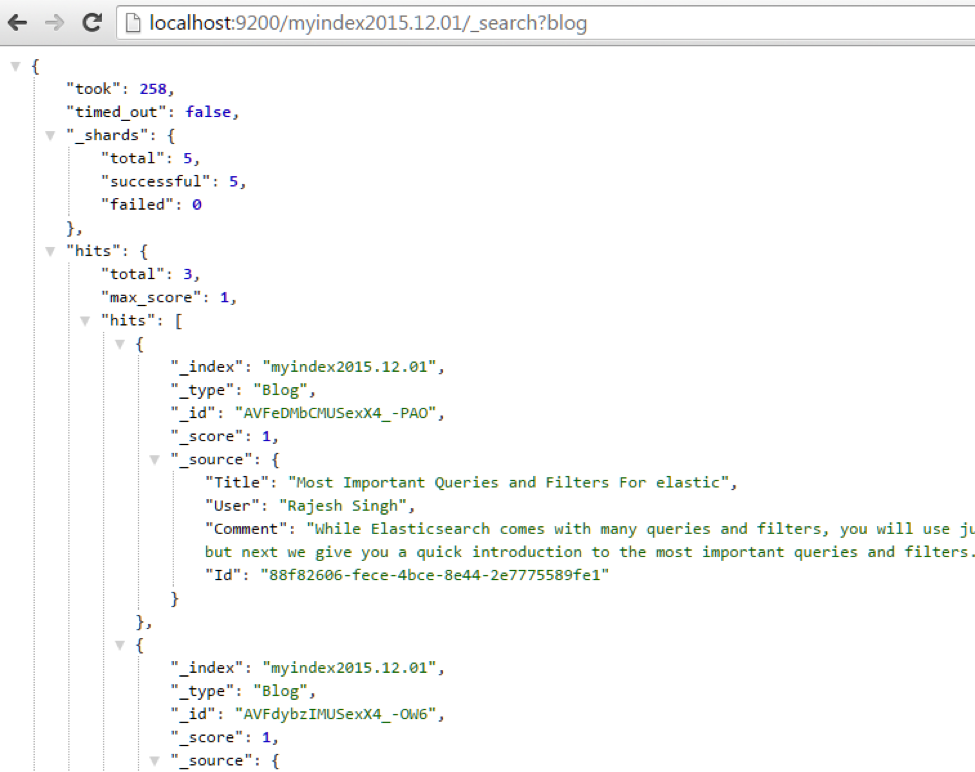
Our index has been created successfully.
Searching in Elastic Search
Now we’ll look at some examples of different searches on the index.
Let’s first search by username, which is a simple search on a column:
string name = "Mahesh Singh";//Console.ReadLine();
var blogs = SearchBlogByName(name);
string output = JsonConvert.SerializeObject(blogs);
Console.WriteLine(output);
Console.ReadLine();
public static List<Blog> SearchBlogByName(string name)
{
ElasticsearchClient _ESClient = new ElasticsearchClient(new ConnectionConfiguration(new Uri("http://localhost:9200")));
string strIndexName = "MyIndex" + DateTime.Now.ToUniversalTime().ToString("yyyy.MM.dd");
string index = "Blog";
string strMatchQuery = @"{""query"":{""bool"":{""must"":{""match"":{""User"":""{0}""}}}},""_source"":true}";
strMatchQuery = strMatchQuery.Replace("{0}", name);
ElasticsearchResponse<DynamicDictionary> esResponse = _ESClient.Search(strIndexName.ToLower(), index, strMatchQuery);
var blogs = new List<Blog>();
if (esResponse.Success == true)
{
Dictionary<string, string> dbQueriesDict = new Dictionary<string, string>();
for (int counter = 0; counter < esResponse.Response["hits"].total; counter++)
{
blogs.Add(new Blog() { Id = esResponse.Response["hits"].hits[0]["_source"].Id.HasValue ? esResponse.Response["hits"].hits[0]["_source"].Id.value : "", User = esResponse.Response["hits"].hits[0]["_source"].User.HasValue ? esResponse.Response["hits"].hits[0]["_source"].User.value : "", Comment = esResponse.Response["hits"].hits[0]["_source"].Comment.HasValue ? esResponse.Response["hits"].hits[0]["_source"].Comment.value : "", Title = esResponse.Response["hits"].hits[0]["_source"].Title.HasValue ? esResponse.Response["hits"].hits[0]["_source"].Title.value : "" });
}
}
return blogs;
}
In the above code, we have used the following query for an exact match:
string strMatchQuery = @"{""query"":{""bool"":{""must"":
{""match"":{""User"":""{0}""}}}},""_source"":true}";
The default match query is of type boo, which means that the text provided is analyzed and the analysis process constructs a Boolean query from the provided text. The operator flag can be set to “or” or “and” to control the Boolean clauses (defaults to or).
So the above query is an exact match query with a must clause (and). You can also use a should clause that is equivalent to “or” operator.
In the following example, we have shown the search on multiple fields with an “or” clause, so the query should be a Boolean query with a “should” clause.
string strMatchQuery = @"{""query"":{""bool"":{""should"":[
{""match"":{""Title"":""" + titleOrComment + @"""}},
{""match"":{""Comment"":""" + titleOrComment + @"""}}
]}},""_source"":true}";
We are matching with a “should” operator in the Boolean query, so either the title or the comment should be a match.
public static List<Blog> SearchBlogByTitleOrComment(string titleOrComment)
{
ElasticsearchClient _ESClient = new ElasticsearchClient(new ConnectionConfiguration(new Uri("http://localhost:9200")));
string strIndexName = "MyIndex" + DateTime.Now.ToUniversalTime().ToString("yyyy.MM.dd");
string index = "Blog";
string strMatchQuery = @"{""query"":{""bool"":{""should"":[{""match"":{""Title"":""" + titleOrComment + @"""}},{""match"":{""Comment"":""" + titleOrComment + @"""}}]}},""_source"":true}";
ElasticsearchResponse<DynamicDictionary> esResponse = _ESClient.Search(strIndexName.ToLower(), index, strMatchQuery);
var blogs = new List<Blog>();
if (esResponse.Success == true)
{
Dictionary<string, string> dbQueriesDict = new Dictionary<string, string>();
for (int counter = 0; counter < esResponse.Response["hits"].total; counter++)
{
blogs.Add(new Blog() { Id = esResponse.Response["hits"].hits[0]["_source"].Id.HasValue ? esResponse.Response["hits"].hits[0]["_source"].Id.value : "", User = esResponse.Response["hits"].hits[0]["_source"].User.HasValue ? esResponse.Response["hits"].hits[0]["_source"].User.value : "", Comment = esResponse.Response["hits"].hits[0]["_source"].Comment.HasValue ? esResponse.Response["hits"].hits[0]["_source"].Comment.value : "", Title = esResponse.Response["hits"].hits[0]["_source"].Title.HasValue ? esResponse.Response["hits"].hits[0]["_source"].Title.value : "" });
}
}
return blogs;
}
One of the biggest advantages of Elastic Search is that you can search partially typed words and misspellings. In the following example, we have shown how a user can enter a misspelling in the FUZZY search and still get data with an approximate match. In this example, the user searched for “surprise” instead of “surprise.”
As shown, a “fuzzy” clause is used for the query:
string query = @"{ ""query"": {
""fuzzy"": { ""text"": { ""value"": """ + text + @""" } } } }";
FuzzySearch("surprize");
public static string FuzzySearch(string text)
{
ElasticsearchClient _ESClient = new ElasticsearchClient(new ConnectionConfiguration(new Uri("http://localhost:9200")));
string strIndexName = "myindex2015.12.01";
string indexType = "FuzzyDemo";
string query = @"{ ""query"": { ""fuzzy"": { ""text"": { ""value"": """ + text + @""" } } } }";
ElasticsearchResponse<DynamicDictionary> esResponse = _ESClient.Search(strIndexName, indexType, query);
string response="";
if (esResponse.Success)
{
for (int counter = 0; counter < esResponse.Response["hits"].total; counter++)
{
response+= esResponse.Response["hits"].hits[0]["_source"];
}
}
return response;
}
The search for “surprise” matches with “Surprise me!”
Output : {"text":"Surprise me!"}
Updating and Deleting a Document
You can easily update or delete a document in an index with the following operations.
string updateQuery = @"{""doc"" : { ""Title"" : """ + blog.Title + @"""}}";
ElasticsearchResponse<DynamicDictionary> esResponse = _ESClient.Update(strIndexName, indexType, blog.Id, updateQuery);
ElasticsearchResponse<DynamicDictionary> esResponse = _ESClient.Delete(strIndexName, indexType, documentId);
Elastic Search Plug-ins
Elastic Search offers a highly useful plugin mechanism as a standard way for extending its core. Plugins enable developers to add a new functionality. There are several plugins available like BigDesk, Head, HQ, Kopf, and Paramedic.
Although Elastic Search is a powerful tool, there are some disadvantages to it. A major concern is security, because it doesn’t provide authentication and has no support for transactions. Elastic Search is also relatively new, so it hasn’t had time to develop mature client libraries and third party tools, which can make development much harder.
Elastic Search is distributed and fairly stable, but backups and durability are not as high a priority as they may be for other data stores. This is important to keep in mind if you are planning on using it as a primary store, because you could lose your data.
References




Stay in Touch
Keep your competitive edge – subscribe to our newsletter for updates on emerging software engineering, data and AI, and cloud technology trends.